LQR Example¶
This notebook demonstrates how to solve a finite-horizon Linear Quadratic Regulator (LQR) problem using a Gaussian Factor Graph in GTSAM. The goal is to minimize a quadratic cost w.r.t. dynamics constraints over a linear dynamical system using factor-graph-based optimization. The results are compared against results from classical Riccati equations. Adapted from https://
Author(s): Zhouyu Zhang

GTSAM Copyright 2010-2025, Georgia Tech Research Corporation, Atlanta, Georgia 30332-0415 All Rights Reserved
Authors: Frank Dellaert, et al. (see THANKS for the full author list)
See LICENSE for the license information
# In colab install gtsam and gtbook
try:
import google.colab
%pip install --quiet gtsam-develop
%pip install --quiet gtbook
except ImportError:
pass # Not in Colab
Proceed (Y/n)? y
Proceed (Y/n)? y
# Import required libraries
import numpy as np
import matplotlib.pyplot as plt
import gtsam
from gtsam import symbol
from gtsam.symbol_shorthand import X, U
import graphviz
from gtbook.display import showDiscrete-Time State-Space Form (2D State: Position and Velocity)¶
We look to work on a 1D double integrator system, in this sense, we define the state and input as:
We can think of it as a linear vehicle for which we can control the gas paddle (acceleration). Then the discrete-time dynamics become:
Where:
So:
LQR Problem Setup¶
We seek to minimize the infinite-horizon cost function:
Choose the weighting matrices:
: penalizes position and velocity
: penalizes control effort
# Define system dynamics: x_{k+1} = A x_k + B u_k
A = np.array([[1.0, 0.1],
[0.0, 1.0]])
B = np.array([[0.005],
[1.0]])
# Define cost matrices: minimize sum of (xᵀQx + uᵀRu)
Q = np.eye(2)
R = np.array([[1.0]])
Graphical Model Representation of Finite-Horizon LQR¶
We formulate the finite-horizon Linear Quadratic Regulator (LQR) problem as a factor graph, allowing us to interpret optimal control as a maximum a posteriori (MAP) estimation problem.
Problem Statement¶
Given discrete-time linear dynamics:
and a quadratic cost function:
we aim to find the state-control sequence minimizing , subject to initial state and dynamics.
MAP Estimation View¶
This control problem is equivalent to a MAP estimation over a factor graph:
This posterior can be written as a product of factors:
Prior Factor (Initial Condition)¶
We encode the prior on the initial state as a Gaussian:
where enforces the initial condition tightly.
Quadratic Cost Factors¶
Each quadratic cost is rewritten via Cholesky decomposition as:
Similarly, for control:
These are soft constraints, penalizing deviation from zero.
Dynamics Constraints (Hard Constraints)¶
Each dynamics equation:
is encoded as a hard constraint, modeled as a Gaussian with zero variance:
This enforces the equality exactly during optimization.
Terminal Cost¶
The terminal cost is also encoded as a soft quadratic factor:
# Horizon of the problem (i.e. how many discrete timesteps we want to consider)
# Note that in python the initial index starts at 0, so the terminal states would be N-1
N = 4
# Cost factors: L such that Q = LᵀL
Lx = np.linalg.cholesky(Q)
Lu = np.linalg.cholesky(R)
# Create a Gaussian factor graph for the linear-quadratic problem
graph = gtsam.GaussianFactorGraph()
initial_values = gtsam.Values()
# Set initial state: x_0 = [0, 1]^T, add a strong prior factor to fix the initial state
x0 = np.array([0.0, 1.0])
prior_noise = gtsam.noiseModel.Isotropic.Sigma(2, 1e-20)
graph.add(gtsam.JacobianFactor(X(0), np.eye(2), x0, prior_noise))
# Cost + dynamics
for k in range(N):
xk = X(k)
uk = U(k)
# Cost factor: x_k^T Q x_k
graph.add(gtsam.JacobianFactor(xk, Lx, np.zeros(2), gtsam.noiseModel.Unit.Create(2)))
# Cost factor: u_k^T R u_k, note that there is no cost term for terminal input
if k < N-1:
graph.add(gtsam.JacobianFactor(uk, Lu, np.zeros(1), gtsam.noiseModel.Unit.Create(1)))
# Dynamics hard constraint factor: x_{k+1} = A x_k + B u_k
if k <= N-2:
xk1 = X(k+1)
graph.add(gtsam.JacobianFactor(
xk1, np.eye(2),
xk, -A,
uk, -B,
np.zeros((2, 1)),
gtsam.noiseModel.Diagonal.Sigmas(np.zeros(2)) # hard constraint
))
# Terminal cost: x_N-1^T Q x_N-1
xN = X(N-1)
graph.add(gtsam.JacobianFactor(xN, Lx, np.zeros(2), gtsam.noiseModel.Unit.Create(2)))# Solve the factor graph and retrieve the results
result = graph.optimize()
states = []
controls = []
for k in range(N):
xk = X(k)
uk = U(k)
states.append(result.at(xk))
if k < N-1:
controls.append(result.at(uk))
states = np.array(states)
controls = np.array(controls)
# Plotting
plt.figure(figsize=(10, 4))
plt.plot(states[:, 0], label='Position')
plt.plot(states[:, 1], label='Velocity')
plt.title('GTSAM-solved State Trajectories')
plt.legend()
states
array([[0. , 1. ],
[0.0968027 , 0.36053946],
[0.13167395, 0.12400146],
[0.14365837, 0.04085496]])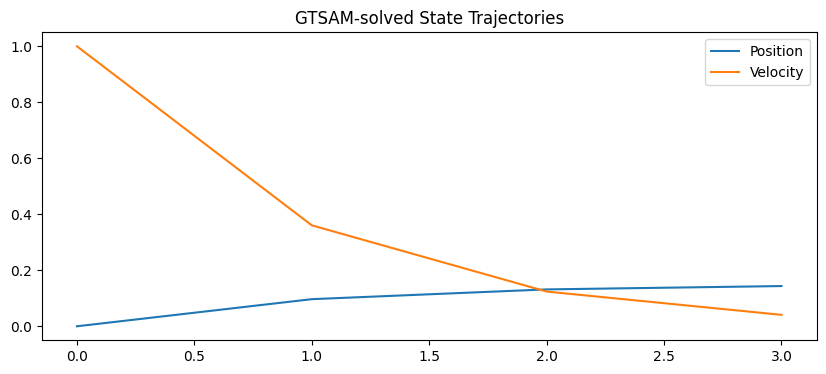
Visualizing the Factor Graph and Variable Elimination (Bayes Net)¶
Initial Factor Graph¶
The first plot generated by graphviz.Source(graph.dot()) visualizes the factor graph representation of the LQR problem.
Ellipses represent variable nodes: states and controls .
Black dots are factor nodes connecting variables — each represents either:
A cost factor (state or control penalty),
A dynamics constraint,
Or a prior (for ).
The structure reflects the temporal nature of the problem:
Each state is connected to its predecessor and successor via dynamics,
Each control connects two consecutive states,
Cost factors attach individually to each and .
graphviz.Source(graph.dot())From Factor Graph to Bayes Net via Variable Elimination¶
After constructing a Gaussian factor graph to represent the finite-horizon LQR problem, we can use GTSAM’s eliminateSequential(ordering) to transform the factor graph into a Bayes Net — a directed acyclic graphical model representing the posterior distribution over all variables in a factored form.
The following plots will visualize the Bayes Net obtained using the elimination order:
Structure of the Bayes Net¶
Each node in the plot represents a variable, and each arrow represents a dependency in a conditional Gaussian distribution arising from the variable elimination process. For example:
⇒
⇒
This structure means that once we solve for the “latest” variable (e.g., ), we can back-substitute through the DAG to recover the entire trajectory.
What Does Elimination Do?¶
In mathematical terms, elimination rewrites the joint Gaussian density:
as a sequence of conditionals:
Each conditional is Gaussian:
This allows us to represent the problem as a triangular system, suitable for efficient solving.
Effect of Elimination Ordering¶
Will the result (optimal trajectory) change if we change the elimination ordering?¶
No — the MAP solution is invariant under ordering for linear-Gaussian systems, because the solution to:
is unique and does not depend on the factorization path.
What changes?¶
Structure of the Bayes Net:
The set of conditionals and their dependencies change. E.g., if we eliminate all controls first, each may depend on more than just , introducing wider conditionals.Computational efficiency:
Different orderings lead to different fill-in patterns during matrix factorization (e.g., Cholesky). A poor ordering increases memory and time.Sparsity pattern:
An optimized ordering (e.g., using COLAMD or METIS) maintains sparse Jacobians and minimal cross-dependencies.Numerical stability (nonlinear problems):
Poor ordering may lead to ill-conditioned systems or less stable Gauss-Newton updates.
Analogy to QR/Cholesky¶
The process is equivalent to structured Gaussian elimination or QR factorization of the system , where variable elimination corresponds to pivoting rows and columns of the matrix in a specific order.
ordering = gtsam.Ordering()
for k in range(N):
ordering.push_back(X(k))
if k < N-1:
ordering.push_back(U(k))
# Generate a reversed ordering from above order
ordering_reversed = gtsam.Ordering()
for k in range(N-1, -1, -1):
ordering_reversed.push_back(X(k))
if k > 0:
ordering_reversed.push_back(U(k-1))
print("Ordering:", ordering_reversed)Ordering: Position 0: x3, u2, x2, u1, x1, u0, x0
dag = graph.eliminateSequential(ordering_reversed)
show(dag, hints={"u":1, "x":0})# The sparse matrix reprenstation of the system
plt.imshow(graph.jacobian(ordering)[0][2:,:], cmap="RdYlGn")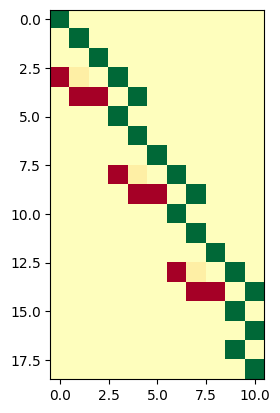
# The resulting Bayesian graph under a different ordering
# The resulting dependency would change, like we have described before
# New ordering
N = 4
ordering = gtsam.Ordering()
for k in range(N-1, -1, -1):
ordering.push_back(X(k))
for k in range(N-1, -1, -1):
if k > 0:
ordering.push_back(U(k-1))
print("New Ordering:", ordering)
dag = graph.eliminateSequential(ordering)
show(dag, hints={"u":1, "x":0})New Ordering: Position 0: x3, x2, x1, x0, u2, u1, u0
Solving the LQR Problem via the Discrete-Time Riccati Equation¶
This code solves a finite-horizon Linear Quadratic Regulator (LQR) problem using the classical backward Riccati recursion followed by a forward rollout of optimal control inputs.
Backward Riccati Recursion¶
We compute the optimal feedback gain by solving the discrete Riccati equation backward from the terminal cost:
The recursion builds the list of gains , used to compute the optimal control law .
Forward Rollout of the Trajectory¶
Given the initial state and feedback gains:
Compute each optimal control input:
Apply dynamics to get the next state:
This yields the full trajectory of states and controls.
# Solve the LQR problem with the classical Riccati equation method
import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import solve_discrete_are
# System definition
A = np.array([[1.0, 0.1],
[0.0, 1.0]])
B = np.array([[0.005],
[1.0]])
Q = np.eye(2)
R = np.array([[1.0]])
x0 = np.array([0.0, 1.0])
N = 3 # Input horizon length (state horizon would be N+1=4)
# Backward Riccati recursion to compute K_t
P = Q.copy() # Terminal cost
K_list = []
for _ in range(N):
S = R + B.T @ P @ B
K = np.linalg.solve(S, B.T @ P @ A) # K = (R + Bᵀ P B)⁻¹ Bᵀ P A
K_list.insert(0, K) # prepend to use forward later
P = Q + A.T @ P @ A - A.T @ P @ B @ K # update P for next step
# Forward rollout of trajectory
x = x0.reshape(-1, 1)
states = [x.flatten()]
controls = []
for K in K_list:
u = -K @ x
controls.append(u.flatten())
x = A @ x + B @ u
states.append(x.flatten())
states = np.array(states)
controls = np.array(controls)
# Plot
plt.figure(figsize=(10, 4))
plt.plot(states[:, 0], label='Position')
plt.plot(states[:, 1], label='Velocity')
plt.title('Riccat-equation-solved State Trajectories')
plt.xlabel('Time step')
plt.legend()
plt.tight_layout()
plt.show()
# Optional: print values
print("States:\n", states)
print("Controls:\n", controls)
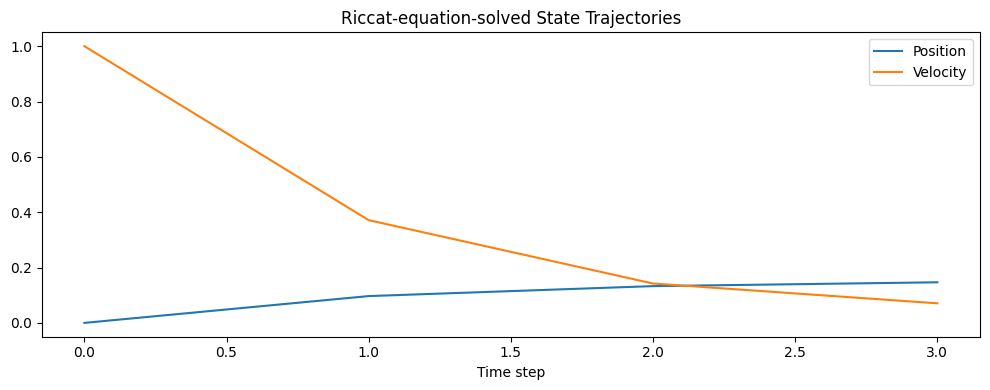
States:
[[0. 1. ]
[0.09685631 0.37126203]
[0.13283732 0.14222434]
[0.14670236 0.07074541]]
Controls:
[[-0.62873797]
[-0.22903769]
[-0.07147893]]